Prometheus 정리
- Sre
- July 10, 2020
프로메테우스란
참고한 자료들
프로메테우스 공식 사이트
https://prometheus.io/docs/introduction/overview/
프로메테우스란
소개
모니터링과 알럿 시스템으로 쿠버네티스에서 주로 사용됩니다.
주요 특징으로는
- 매트릭스 이름과 키-밸류로 식별된 시계열 데이터가 있는 다차원 모델
- PromQL, 유연한 쿼리 언어 치수 활용
- 분산 스토리지에 대한 의존도 없음, 단일 서버의 노드들은 자동임
- 시계열 콜렉션은 HTTP 너머의 모델을 경유하여 끌어오기 발생
- Pushing 시계열은 중개 게이트웨이를 경유하여 제공한다.
- 타겟은 서비스 탐색 또는 고정 환경 설정 경유하여 탐색 된다.
- 그래프의 여러 모드와 대시보드 지원
등이 있습니다.
구성 크게 6가지를 보면 되는데
- 타임 시리즈 데이터를 스크랩 하고 저장 하는 주요 프로메테우스 서버
- 어플리케이션 코드 계측을 위한 클라이언트 라이브러리
- 단기 작업 지원을 위한 푸시 게이트웨이
- 푸시 게이트 웨이란: 임시적으로 존재하며 매트릭을 배치로 프로메테우스에게 노출 시킨다. 스크랩하기 충분하게 긴 시간을 존재하는 종류는 아니기에 push gateway에 매트릭을 푸시하고 push gateway 에서 프로메테우스로 보낸다.
- HAProxy, StatsD, Graphite와 같은 서비스를 위한 특정 목적의 exporter(수출업자?)
- 알럿을 컨트롤 할 수 있는 알럿 매니저
- 여러 지원 툴
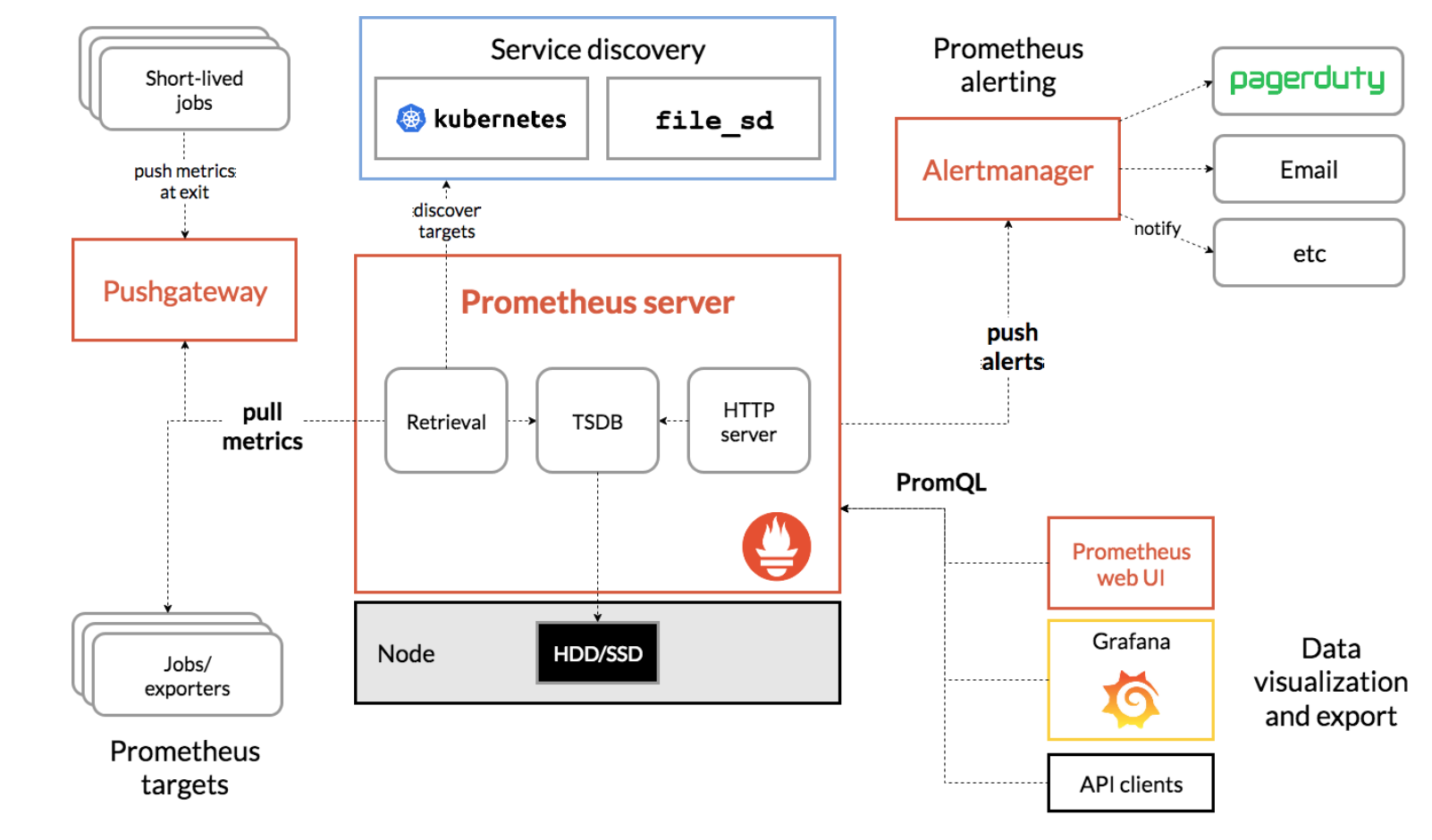
여기서 눈여겨봐야 할 부분은 Pushgate way와 pull metrics입니다.
공부하다가 알게 된 내용은 기존의 모니터링은 로그나 매트릭 정보가 있으면 push로 모니터링 서버에 밀어 넣습니다.
근데 여기서는 pull 방식을 사용합니다. 이 부분을 기억하고 앞으로 나올 풀방식과 푸쉬방식의 차이점을 주의 깊게 읽으면 이해에 큰 도움을 될겁니다.
아무튼 프로메테우스는 모든 순수 숫자 시계열 기록에 대해서는 잘 됩니다. 매우 역동적인 서비스 지향과 기계 중심의 모니터링에도 적합합니다.
마이크로 서비스의 세계에서 다차원 데이터 수집 및 쿼리에 대한 지원은 특히 강점입니다.
문제를 신속하게 진단 할 수 있도록 중단 중에 이동하는 시스템으로 신뢰성을 위해 설계했습니다.
각 프로메테우스 서버는 독립적이고, 네트워크 저장소나 다른 원격 서비스 위에서 의존하지 않습니다.
그러므로 안전합니다.
하지만 단점도 있습니다.
대표저으로 정확도가 중요한 모니터링이 필요할때는 적합하지 않습니다.
프로메테우스의 가치는 안정성, 항상 시스템에 대한 허용 통계를 항상 볼 수 있다는 것입니다. 심지어 오류 조건 하에서도요.
만약 비용 청구와 같이 100프로 정확도를 요구한다면 적절하지 않을 것 같습니다.
왜냐하면 수집된 데이터가 충분히 상세하지 않기 때문이다.
프로메테우스를 사용하는 이유
그렇다면 왜 사용할 까요??
프로메테우스를 사용하는 이유는 많은데
- APM(Application Performance Management) 구축을 목적으로 할 경우
- 다차원 데이터 모델
- 키-값 기반의 모델로 라벨을 이용하여 인프라를 관리하는 쿠버네티스의 방법과의 높은 유사성.
- 유연성 있고 시계열 데이터 그리고 프로메테우스 쿼리 언어 전력(?),
- 액세스 포맷과 프로토콜
- 프로메테우스 매트릭스 노출은 매우 간단한 작업, 매트릭은 사람이 읽기 쉽고 자명한 형식이며 표준 HTTP 전송을 사용하고 게시.
- 웹 브라우저를 이용해서 매트릭이 제대로 노출 되는지 체크가 가능함
서비스 디스커버리
푸시 방식이 아닌 풀 방식으로 자동으로 타겟을 스크랩 할 수 있는 서버를 여러개 가지고 있습니다. 그 중 몇개는 필터링 하고 컨테이너 메타 데이터와 일치 할 수 있도록 구성(configure)이 가능합니다.
그러므로 일시적인 Kubernetes 워크로드에 적합.
모듈식 고가용성 구성(component)
매트릭 수집, 알림, 시각화 등 다른 구성 할수 있는 서비스로 효과를 냄, 이러한 모든 서비스들은 중복성과 샤딩을 할 수 있도록 지원 해줍니다.
풀방식과 푸시 방식(개인적으로 중요하다 생각)
푸시 방식은 각 agent에서 매트릭 로그를 수집 그리고 이를 queue로 송부 (queue는 콜렉터에서 취합 수집 서버의 부하를 막기위해 앞단 queue에 딜레이를 주는 방식입니다.)
이러한 부분이 즉시성을 보장해야하는 모니터링 시스템에 맞지 않습니다. 매트릭 정보가 바뀔 때마다 Agent에 일괄 배포해야 하기 때문입니다.
이러다보니 부하 문제가 발생 할 수 있습니다. 아이러니하게도 모니터링을 위한 모니터링 시스템 및 배포 시스템을 별도로 구성을 해야합니다.
프로메테우스의 가장 큰 장점은 프로메테우스에서 장애가 생기거나 트래픽 부하 등으로 인해 모니터링을 일시적으로 중단한다고 해도 애플리케이션에게는 아무런 문제가 되지 않는 것입니다.
애플리케이션 입장에서는 Matrics Endpoint를 준비해 놓고 누군가가 가져가기를 하염없이 기다리기만 하면 됩니다.
풀 방식은 각 수집서버에서 필요한 매트릭만 긁어오는 것 이기에 부하가 조절 가능하며, 어플리케이션에서 무리 없이 사용 가능합니다.
단점은 Scale-out이 안된다는 것입니다. Prometheus를 여러대에 구성해서 사용하려면 Prometheus에 Prometheus를 연결해서 Hierachy구조를 만들어서 사용해야 합니다.
그러다 보면 자연스레 구성이 복잡해집니다.
(Scale-out 문제는 또 다른 오픈소스인 Thanos를 사용하면 된다고 합니다.)
또 다른 단점은 대략적인 매트릭 추세를 파악하기에는 좋지만, APM에서 필요한 모든 지표를 추적해 조정을 하기에는 적합하지 않습니다.
그리고 가변적인 상황에서는 풀 방식이 불리한데 대표적으로 오토스케일링시 추가된 Pod들은 설정 파일에 IP가 없어 모니터링 대상에서 제외됩니다.
위와 같은 단점을 해결하기 위해 앞서 프로메테우스 구성도에 나와있는 요소 중 가운데 상단에 있는 Service discovery로 추가된 Pod를 Pull하여 조회 할 수 있습니다.
저장방식
프로메테우스 내의 메모리와 로컬디스크에 저장이 됩니다. 설치가 매우 쉽지만 반대로 스케일링이 불가능합니다 구조상 HA(High Availability- 이중화)나 클러스터링이 불가능합니다. (샤딩(sharding)으로 해결하는데 이 방법은 타노스로 구현이 가능하다고 합니다.)
여기까지가 프로메테우스에 대한 간단한 내용이었습니다.
자세한 내용은 어디까지나 공식 홈페이지에서 보시는게 가장 정확할 것으로 보입니다.